













Cassandra Stress
The cassandra-stress tool is used to benchmark and load-test a Cassandra
cluster.
cassandra-stress supports testing arbitrary CQL tables and queries, allowing users to benchmark their own data model.
This documentation focuses on user mode to test personal schema.
Usage
There are several operation types:
-
write-only, read-only, and mixed workloads of standard data
-
write-only and read-only workloads for counter columns
-
user configured workloads, running custom queries on custom schemas
The syntax is cassandra-stress <command> [options].
For more information on a given command or options, run cassandra-stress help <command|option>.
- Commands
-
- read:
-
Multiple concurrent reads - the cluster must first be populated by a write test
- write:
-
Multiple concurrent writes against the cluster
- mixed:
-
Interleaving of any basic commands, with configurable ratio and distribution - the cluster must first be populated by a write test
- counter_write:
-
Multiple concurrent updates of counters.
- counter_read:
-
Multiple concurrent reads of counters. The cluster must first be populated by a counterwrite test.
- user:
-
Interleaving of user provided queries, with configurable ratio and distribution.
- help:
-
Print help for a command or option
- print:
-
Inspect the output of a distribution definition
- legacy:
-
Legacy support mode
- Primary Options
-
- -pop:
-
Population distribution and intra-partition visit order
- -insert:
-
Insert specific options relating to various methods for batching and splitting partition updates
- -col:
-
Column details such as size and count distribution, data generator, names, comparator and if super columns should be used
- -rate:
-
Thread count, rate limit or automatic mode (default is auto)
- -mode:
-
Thrift or CQL with options
- -errors:
-
How to handle errors when encountered during stress
- -sample:
-
Specify the number of samples to collect for measuring latency
- -schema:
-
Replication settings, compression, compaction, etc.
- -node:
-
Nodes to connect to
- -log:
-
Where to log progress to, and the interval at which to do it
- -transport:
-
Custom transport factories
- -port:
-
The port to connect to cassandra nodes on
- -graph:
-
Graph recorded metrics
- -tokenrange:
-
Token range settings
- Suboptions
-
Every command and primary option has its own collection of suboptions. These are too numerous to list here. For information on the suboptions for each command or option, please use the help command,
cassandra-stress help <command|option>.
User mode
User mode allows you to stress your own schemas, to save you time in the long run. Find out if your application can scale using stress test with your schema.
Profile
User mode defines a profile using YAML. Multiple YAML files may be specified, in which case operations in the ops argument are referenced as specname.opname.
An identifier for the profile:
specname: staff_activitiesThe keyspace for the test:
keyspace: staffCQL for the keyspace. Optional if the keyspace already exists:
keyspace_definition: |
CREATE KEYSPACE stresscql WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 3};The table to be stressed:
table: staff_activitiesCQL for the table. Optional if the table already exists:
table_definition: |
CREATE TABLE staff_activities (
name text,
when timeuuid,
what text,
PRIMARY KEY(name, when, what)
)Optional meta-information on the generated columns in the above table. The min and max only apply to text and blob types. The distribution field represents the total unique population distribution of that column across rows:
columnspec:
- name: name
size: uniform(5..10) # The names of the staff members are between 5-10 characters
population: uniform(1..10) # 10 possible staff members to pick from
- name: when
cluster: uniform(20..500) # Staff members do between 20 and 500 events
- name: what
size: normal(10..100,50)Supported types are:
An exponential distribution over the range [min..max]:
EXP(min..max)An extreme value (Weibull) distribution over the range [min..max]:
EXTREME(min..max,shape)A gaussian/normal distribution, where mean=(min+max)/2, and stdev is (mean-min)/stdvrng:
GAUSSIAN(min..max,stdvrng)A gaussian/normal distribution, with explicitly defined mean and stdev:
GAUSSIAN(min..max,mean,stdev)A uniform distribution over the range [min, max]:
UNIFORM(min..max)A fixed distribution, always returning the same value:
FIXED(val)If preceded by ~, the distribution is inverted
Defaults for all columns are size: uniform(4..8), population: uniform(1..100B), cluster: fixed(1)
Insert distributions:
insert:
# How many partition to insert per batch
partitions: fixed(1)
# How many rows to update per partition
select: fixed(1)/500
# UNLOGGED or LOGGED batch for insert
batchtype: UNLOGGEDCurrently all inserts are done inside batches.
Read statements to use during the test:
queries:
events:
cql: select * from staff_activities where name = ?
fields: samerow
latest_event:
cql: select * from staff_activities where name = ? LIMIT 1
fields: samerowRunning a user mode test:
cassandra-stress user profile=./example.yaml duration=1m "ops(insert=1,latest_event=1,events=1)" truncate=onceThis will create the schema then run tests for 1 minute with an equal number of inserts, latest_event queries and events queries. Additionally the table will be truncated once before the test.
The full example can be found here:
spacenam: example # idenitifier for this spec if running with multiple yaml files
keyspace: example
# Would almost always be network topology unless running something locally
keyspace_definition: |
CREATE KEYSPACE example WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 3};
table: staff_activities
# The table under test. Start with a partition per staff member
# Is this a good idea?
table_definition: |
CREATE TABLE staff_activities (
name text,
when timeuuid,
what text,
PRIMARY KEY(name, when)
)
columnspec:
- name: name
size: uniform(5..10) # The names of the staff members are between 5-10 characters
population: uniform(1..10) # 10 possible staff members to pick from
- name: when
cluster: uniform(20..500) # Staff members do between 20 and 500 events
- name: what
size: normal(10..100,50)
insert:
# we only update a single partition in any given insert
partitions: fixed(1)
# we want to insert a single row per partition and we have between 20 and 500
# rows per partition
select: fixed(1)/500
batchtype: UNLOGGED # Single partition unlogged batches are essentially noops
queries:
events:
cql: select * from staff_activities where name = ?
fields: samerow
latest_event:
cql: select * from staff_activities where name = ? LIMIT 1
fields: samerow- Running a user mode test with multiple yaml files
-
cassandra-stress user profile=./example.yaml,./example2.yaml duration=1m "ops(ex1.insert=1,ex1.latest_event=1,ex2.insert=2)" truncate=once This will run operations as specified in both the example.yaml and example2.yaml files. example.yaml and example2.yaml can reference the same table, although care must be taken that the table definition is identical (data generation specs can be different).
Lightweight transaction support
cassandra-stress supports lightweight transactions. To use this feature, the command will first read current data from Cassandra, and then uses read values to fulfill lightweight transaction conditions.
Lightweight transaction update query:
queries:
regularupdate:
cql: update blogposts set author = ? where domain = ? and published_date = ?
fields: samerow
updatewithlwt:
cql: update blogposts set author = ? where domain = ? and published_date = ? IF body = ? AND url = ?
fields: samerowThe full example can be found here:
# Keyspace Name
keyspace: stresscql
# The CQL for creating a keyspace (optional if it already exists)
# Would almost always be network topology unless running something locall
keyspace_definition: |
CREATE KEYSPACE stresscql WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
# Table name
table: blogposts
# The CQL for creating a table you wish to stress (optional if it already exists)
table_definition: |
CREATE TABLE blogposts (
domain text,
published_date timeuuid,
url text,
author text,
title text,
body text,
PRIMARY KEY(domain, published_date)
) WITH CLUSTERING ORDER BY (published_date DESC)
AND compaction = { 'class':'LeveledCompactionStrategy' }
AND comment='A table to hold blog posts'
### Column Distribution Specifications ###
columnspec:
- name: domain
size: gaussian(5..100) #domain names are relatively short
population: uniform(1..10M) #10M possible domains to pick from
- name: published_date
cluster: fixed(1000) #under each domain we will have max 1000 posts
- name: url
size: uniform(30..300)
- name: title #titles shouldn't go beyond 200 chars
size: gaussian(10..200)
- name: author
size: uniform(5..20) #author names should be short
- name: body
size: gaussian(100..5000) #the body of the blog post can be long
### Batch Ratio Distribution Specifications ###
insert:
partitions: fixed(1) # Our partition key is the domain so only insert one per batch
select: fixed(1)/1000 # We have 1000 posts per domain so 1/1000 will allow 1 post per batch
batchtype: UNLOGGED # Unlogged batches
#
# A list of queries you wish to run against the schema
#
queries:
singlepost:
cql: select * from blogposts where domain = ? LIMIT 1
fields: samerow
regularupdate:
cql: update blogposts set author = ? where domain = ? and published_date = ?
fields: samerow
updatewithlwt:
cql: update blogposts set author = ? where domain = ? and published_date = ? IF body = ? AND url = ?
fields: samerowGraphing
Graphs can be generated for each run of stress.
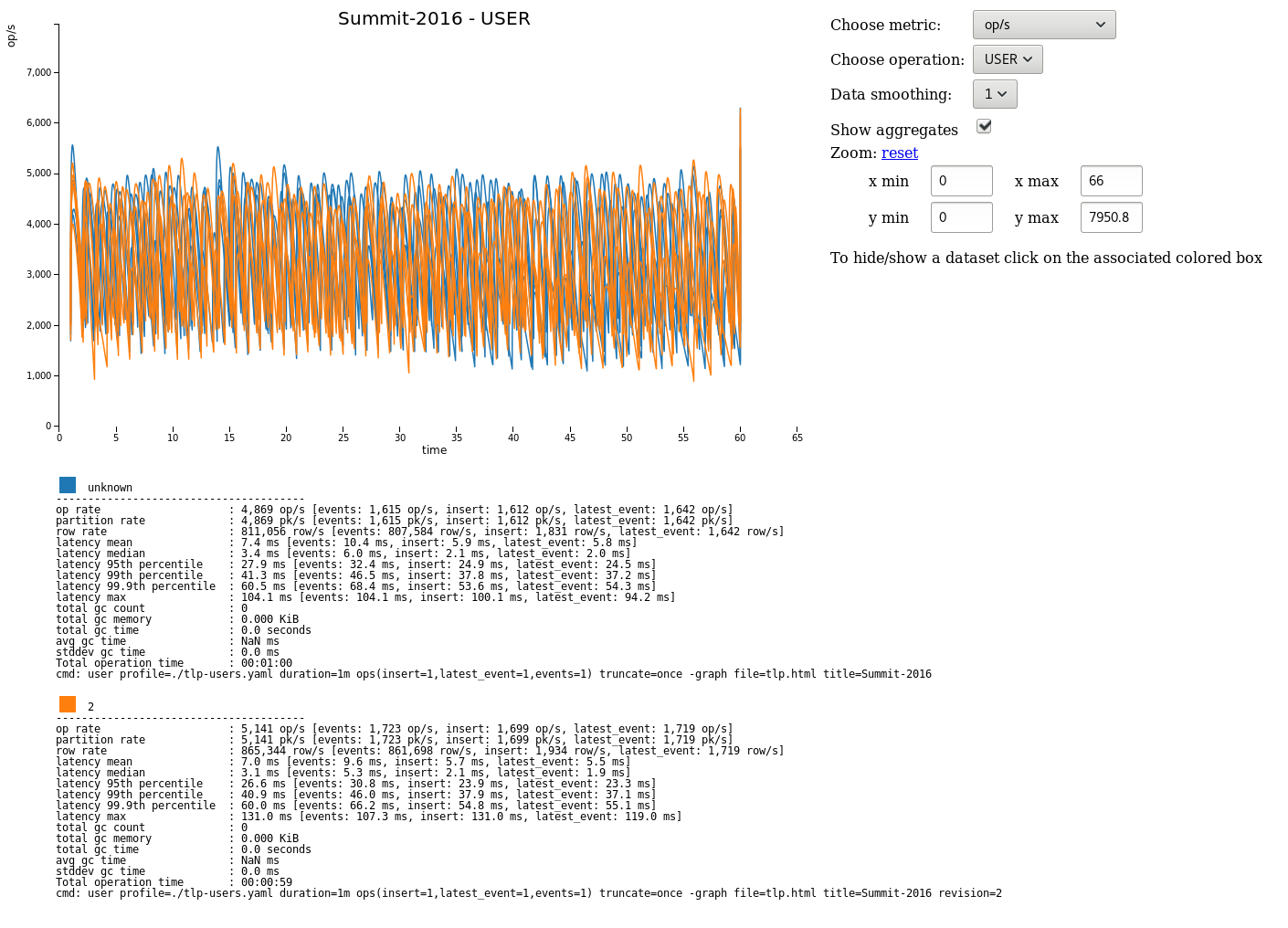
To create a new graph:
cassandra-stress user profile=./stress-example.yaml "ops(insert=1,latest_event=1,events=1)" -graph file=graph.html title="Awesome graph"To add a new run to an existing graph point to an existing file and add a revision name:
cassandra-stress user profile=./stress-example.yaml duration=1m "ops(insert=1,latest_event=1,events=1)" -graph file=graph.html title="Awesome graph" revision="Second run"FAQ
How do you use NetworkTopologyStrategy for the keyspace?
Use the schema option making sure to either escape the parenthesis or enclose in quotes:
cassandra-stress write -schema "replication(strategy=NetworkTopologyStrategy,datacenter1=3)"How do you use SSL?
Use the transport option:
cassandra-stress "write n=100k cl=ONE no-warmup" -transport "truststore=$HOME/jks/truststore.jks truststore-password=cassandra"Is Cassandra Stress a secured tool?
Cassandra stress is not a secured tool. Serialization and other aspects of the tool offer no security guarantees.